
PDF 파일 텍스트 글자 추출 방법: 무료 문자 인식 프로그램
복사가 안 되는 PDF 파일에서 텍스트, 글자를 추출하는 방법에 대해서 알아보겠습니다. 텍스트를 복사하려고 하는데 마우스 드래그가 안 될 때가 있는데 이 경우 무료 문자 인식 프로그램(OCR)을 이용해서 텍스트를 추출할 수 있습니다.
일반적으로 PDF를 만들 때 워드나 한글, 엑셀 등의 문서 프로그램을 이용해서 PDF를 저장하는데 이렇게 파일을 제작하면 마우스로 드래그해서 복사 후 붙여넣기가 가능합니다. 그러나 문서가 아닌 이미지 파일(스캔 파일 등)로 PDF 파일을 만드는 경우 드래그 자체가 불가능하기 때문에 텍스트를 복사를 할 수 없죠. 이럴 때는 스마트폰의 문자 인식 프로그램처럼 PC에서 OCR 문자인식 기능을 이용해야 합니다.
PDF 텍스트 글자 추출 방법
무료 PDF 문자 인식 프로그램 중 가장 좋은 것이 바로 "알PDF"입니다. 개인적으로 알프로그램들이 광고가 많아서 선호하지는 않지만 무료이기 때문에 감안하고 사용하고 있습니다.
문자 인식(OCR) 기능을 이용하려면 알PDF 설치 후 OCR 프로그램을 추가로 설치해 주어야 합니다.
- 알PDF에서 복사가 안 되는 스캔 이미지 PDF 파일을 열어 줍니다. 그리고 상단 메뉴에서 "도구 > 문자인식(OCR)"을 클릭합니다.
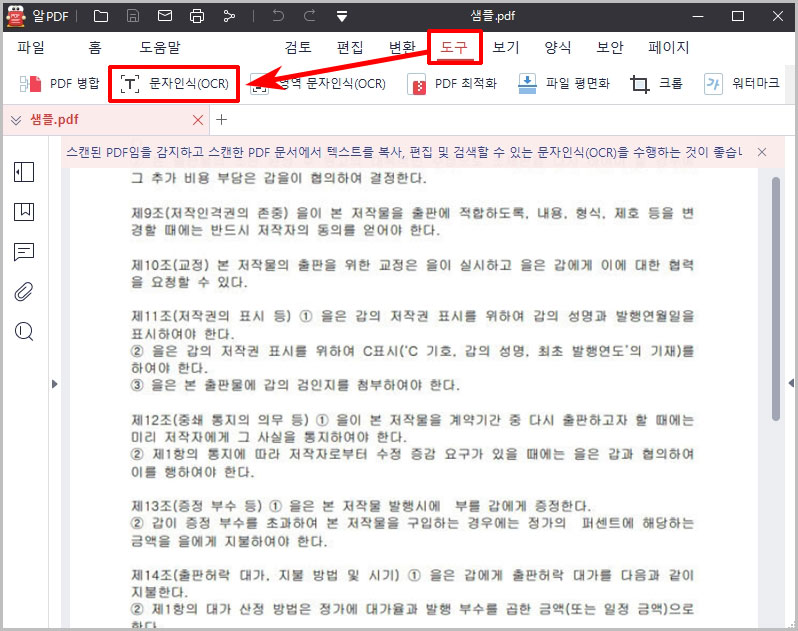
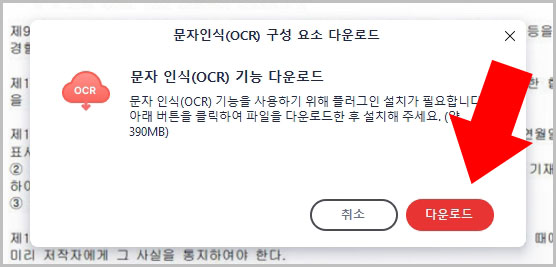
- 문자 인식(OCR) 기능 다운로드를 한 후 파일을 또 설치해 줍니다. (OCR 파일 설치 후 알PDF를 재시작해 주세요.)
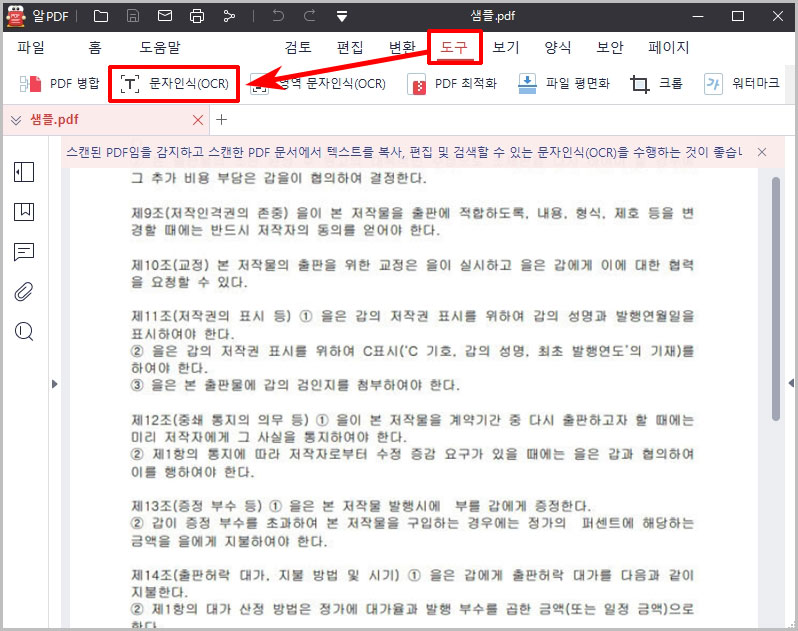
- 알PDF 재시작 후 다시 파일을 열고 동일하게 "도구 > 문자인식(OCR)"을 클릭합니다.
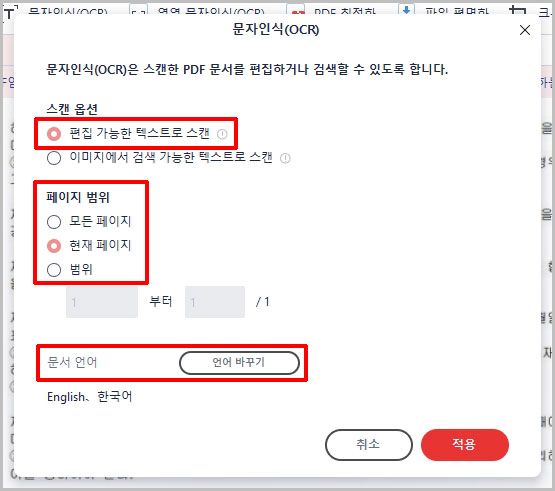
- 스캔 옵션에서 편집 가능한 텍스트로 스캔을 선택하고 페이지 범위 설정 후 적용을 클릭합니다.(문서가 외국어로 되어 있다면 문서 언어 바꾸기를 이용해서 인식 언어를 변경해 주세요.)
- 문자인식이 진행됩니다.
- 그러면 이렇게 스캔된 파일도 마우스 드래그가 가능하고 Ctrl+C, Ctrl+V를 이용해서 복사&붙여넣기가 가능해집니다.
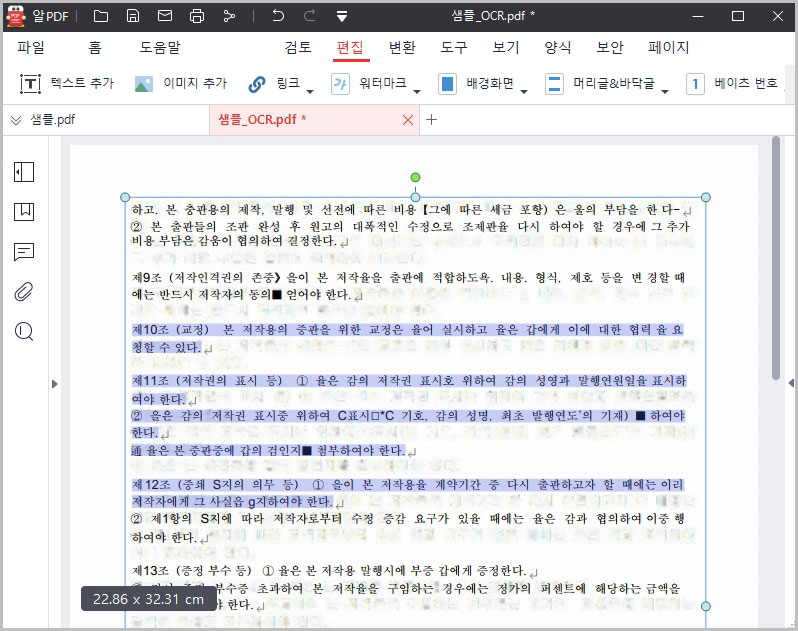
참고로 이미지로 된 PDF 파일의 화질이 좋아야 텍스트 추출 성능이 좋아집니다. 글자가 흐릿하거나 스캔 상태가 안 좋은 문서들은 제대로 추출이 안 될 수 있으니 유의하시기 바랍니다.
추천 글 더 보기
>> PDF 워터마크 만들기: 텍스트 이미지 간단 삽입 방법
>> PDF 용량 줄이기: 원본 10분의 1까지 압축 가능




댓글